[Note: I wrote this piece on 29 December 2011, but I'm adding it to my blog today, 27 January 2016. Today was the release of the first Go playing program that can defeat a grandmaster]
In the year 1770, two centuries before the creation of the first general-purpose electronic computer, a man named Wolfgang von Kempelen constructed a seemingly impossible machine. The machine was known as The Turk, and it was an automaton with the ability to play chess. The robot was shaped like a human with Turkish clothes sitting in front of a desk, and was known to have won in chess against people such as Napoleon Bonaparte and Benjamin Franklin. The Turk, however, after 50 years of exhibition, was revealed to be a hoax. It contained an intricate system that allowed a human player hiding inside the desk to decide the next move (Schaffer, pp. 126-165). Artificial intelligence is a topic that has fascinated people even before computers existed, but now that they exist, how does a computer “think” in order to play a board game like chess?

The Turk
Defining AI
Artificial Intelligence is a very broad field of Computer Science. In the general sense, we can define AI as the study of rational agents. A rational agent is any program that “reads” an environment with sensors and performs rational actions on this environment through what we call actuators. A self-driving car, for example, might use a camera as a sensor, and steering, acceleration, and breaking as its actuators. This car would act rationally on its environment, the road, so as to avoid obstacles and reach its destination. An AI environment can be either discrete or continuous, like the board for a chess-playing agent or the road for the mentioned self-driving car, respectively. The environment can also be either deterministic, if the next state of the environment is completely determined by the current state and the action performed by the rational agent, like in checkers, or stochastic, where there is an element of chance that affects the outcome of the action of the agent, like in the card game Blackjack. An environment can also be either fully observable like in solving a Rubik’s cube, where the entire state of the game is known, or partially observable, like in a labyrinth, where the agent does not know everything about the state of the environment. An environment can have the property of being dynamic, where the environment can change while the agent is making a decision, like in timed chess or a self-driving car, or static, where the environment remains constant until the agent deliberates a decision. It can be episodic or sequential, where in the former what the agent experiences is divided into independent, single-action episodes, like a robot that classifies candy by color, and in the latter the actions of the agent affect further actions. Finally, an environment can be single-agent, where only one agent affects the environment, or multi-agent, where more than one agent compete against or collaborate with each other. (Russel, pp. 34-44)
As we can see, AI encompasses a lot of different types of environments. In this chapter, we will be specifically dealing with techniques for solving discrete, fully observable, static, sequential, two-player, turn-based, adversarial board games.
Tic-Tac-Toe
In tic-tac-toe, before a human player makes a move, he or she usually considers the consequences of such move, evaluating if it is a winning move and predicting what the opponent will do on the next turn. Similarly, before choosing a move, we can make a program that plays tic-tac-toe by testing every legal move it can make, then considering every possibility the opponent has after this move, then every possibility the computer has after that, and so on. For this, we create a game tree, a tree where each node represents a state of the game (the location of each piece and the player whose turn it is), each edge represents a move, and the root node represents the start state, in this case the empty 3x3 board, where it is X’s turn to play. In order to choose the next move to make, our program can do a complete traversal on this tree in order to determine which move leads to the maximum number of possible wins assuming the opponent always plays its best move (this is called the minimax algorithm) (Russel, pp. 161-163). The game of tic-tac-toe is considered solved in the field of Artificial Intelligence since a computer can always know what the outcome of a given game will be if both players play optimally.
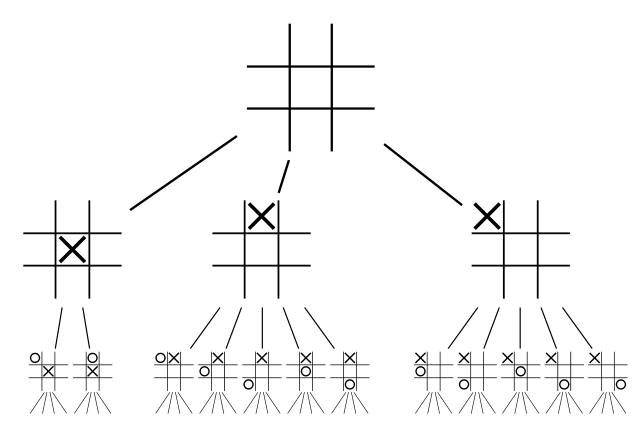
A partial tic-tac-toe game tree
Chess
Chess is another game that can be played by a computer. One would think that a computer would be able to traverse the entire game tree in chess, as with tic-tac-toe, and be able to determine the most favorable strategy. However, chess has a bigger board (8 by 8) than tic-tac-toe, more types of pieces, more rules, and longer games in terms the amount of moves. This causes the game tree for chess to have a higher branching factor and a greater depth, greatly increasing the number of nodes to traverse as compared to tic-tac-toe. According to information theorist Claude Shannon, in his 1950 paper "Programming a Computer for Playing Chess," “A machine operating at the rate of one variation per microsecond would require over 1090 years to calculate the first move!” A modern computer running at one variation per nanosecond would take over 1087 years, a significant improvement in theory, but not in practice!
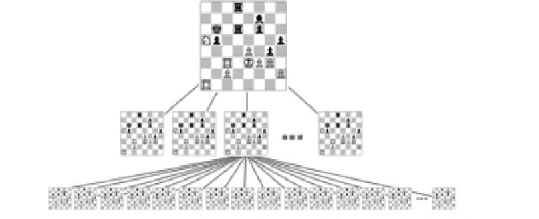
A partial chess game tree
If a game tree traversal is not feasible for chess, how is it that computers are nowadays able to defeat chess grandmasters? Computers use additional optimization techniques. The basic idea is to be able to stop the search on the tree at a certain point and be able to evaluate the current position without additional search. We evaluate the current position using an evaluation function, which is hard-coded into the program and given a position returns an integer indicating how convenient the position is. The this evaluation function varies from program to program, but it might, for example, give a higher score for having a central position, or open files, or more pieces than the opponent, or any combination of these. The only condition is that the function is based solely on the current position.
Another optimization technique that is used is retrograde analysis. This technique consists of working backwards though the game tree from common, known checkmates, repeatedly calculating what positions could have been the previous ones. By doing this, we can create an endgame tablebase, which is a database with the optimal move given a position during endgame. This technique is only feasible for late game when not many pieces remain on the board, but if used right, it is a powerful technique, since forwards decision tree traversal is weak in these situations.
In Computer Science, chess is considered partially solved, since it is not currently possible for a computer to know the outcome of any given game if both players play optimally; this is only possible for endgames, as seen above.
Go
Go is a very interesting game in the field of AI; no computer program can currently play Go to a level above the one of human players. The game board is a 19x19 grid and the pieces can be placed without many restrictions: on any open position. This gives the game tree an incredibly big branching factor, much bigger than the one in chess. Additionally, unlike in chess where the game becomes simpler as the game progresses and players capture pieces, Go usually becomes more complex as the game advances, and it is not practical to perform a retrograde analysis. Additionally, it is difficult to create a good evaluation function for this game, by the nature of the trade-offs existent in this game. Our traditional search seems to be practically worthless here, so we need other techniques along with this search.
One of the additional techniques that are used is Monte Carlo tree search. In general, a Monte Carlo method involves using a great amount of random samplings in order to compute something. In a Monte Carlo tree search for Go, for each edge branching out of the current state of the game, we simulate thousands of random games starting with that move, and then choose the move with the best set of resulting games. The advantage of this technique is that we do not need to device an evaluation function, since we simulate each game completely, reaching a leaf node each time. Even though a Monte Carlo tree search provides a strong overall strategy, it might overlook one particularly strong response from the opponent if all other responses are weak. This shortfall can be ameliorated by doing a limited depth normal tree search before generating moves and by adding some knowledge to the move selection rather than selecting moves completely randomly.
Another additional method used is machine learning, where a program previously plays hundreds of games, and modifies the values of its given parameters to improve its performance. The advantage of this method, like with the Monte Carlo method, is that the program develops its own rules and strategies instead of depending on hard-coded ones.
Like with chess, Go is considered partially solved. The game is solved on the smaller 4x4 and 5x5 boards, but, as we have seen, computers show a very weak play for matches on the regular 19x19 board.
Backgammon
The games we have seen so far have all been deterministic, so now we will consider the stochastic game of backgammon. In this game, dice rolls add the element of randomness to the game. Many strong backgammon programs use a form of machine learning called neural networks. This simulates a network of neurons to gain experience from previous games, but their explanation is beyond the scope of this essay. This technique allows us to let a backgammon program play against itself hundreds or thousands of times beforehand, developing a playing strategy that, in the case of backgammon, has been able to win against most human players.
***
Artificial Intelligence is a very broad and fascinating topic that has become increasingly popular with time. The known methods of solving AI problems might seem cryptic at first, but they become intuitive when we understanding the data structures they need and their underlying motivation. Even though the technologies in Artificial Intelligence are very advanced, like we have seen with chess-playing computers that can beat grandmasters, there is still much progress to be made. Perhaps some day computers will be able to play Go at the level of a grandmaster. Perhaps users will be able to play chess during a road trip while their car drives them to their destination.
Works Cited:
Russel, Stuart, and Peter Norvig. Artificial Intelligence: A Modern Approach. Upper Saddle River, NJ:Prentice Hall, 2010. Print.
Schaffer, Simon, The Sciences in Enlightened Europe, Chicago: The University of Chicago Press, 1999. Print.
Shannon, Claude E., “Programming a Computer for Playing Chess”, Philosophical Magazine Murray Hill, N.J., 1950. Print.